
Dictionaries, Part 2
Remember letter count
def letter_count(word):
# create an empty dictionary
result = {}
for letter in word:
# if this letter is not there, initialize a new dictionary entry
if letter not in result:
result[letter] = 0
# now we can be sure the entry is there, so increment it
result[letter] += 1
return result
letter_count('supply') {'s': 1, 'u': 1, 'p': 2, 'l': 1, 'y': 1}Important pattern:
- create an empty dictionary
- loop through all the keys you want to create
- if a key is not in the dictionary, initialize a new entry
- increment the value for this key
Let’s revisit census counting
- create an empty dictionary
- loop through all the lines in the file
- split and unpack each line
- convert age to an integer
- round age to nearest 10
- if an age range is not in the dictionary, initialize a new entry for this key
- increment the number of people in that age range
def round_to_nearest_10(number):
remainder = number % 10
return number - remainder
def census_age_count(filename):
age_count = {}
with open(filename) as file:
for line in file:
last, first, relationship, gender, race, age, marital_status = line.strip().split(',')
age = int(age)
age_group = round_to_nearest_10(age)
if age_group not in age_count:
age_count[age_group] = 0
age_count[age_group] += 1
return age_count
census_age_count('census.txt') {50: 2, 30: 1, 10: 4, 20: 5}Dictionaries can store anything for values
- typically integers or characters for keys
- but values can be anything
Example — parsing email addresses
- we have a list of email addresses:
['[email protected]', '[email protected]', '[email protected]']- build a dictionary that lists all the users with the same email provider
{'gmail.com': ['abby', 'rachel']
'yahoo.com': ['kumar']
}- keep in mind the types
- keys will be a string
- values will be a list of strings
{'gmail.com': ['abby', 'rachel']
'yahoo.com': ['kumar']
}def email_hosts(emails):
hosts = {}
for email in emails:
# parse the email address to find the username part and the host part
at = email.find('@')
username = email[:at]
host = email[at + 1:]
# rest of code here
pass
return hostsdef email_hosts(emails):
hosts = {}
for email in emails:
# parse the email address to find the username part and the host part
at = email.find('@')
username = email[:at]
host = email[at + 1:]
# initialize entry
if host not in hosts:
hosts[host] = []
# increment/append
users = hosts[host]
users.append(username)
return hosts- lets look at this portion carefully:
# increment/append
users = hosts[host]
users.append(username)- we could also do this in one step
hosts[host].append(username)def email_hosts(emails):
hosts = {}
for email in emails:
# parse the email address to find the username part and the host part
at = email.find('@')
username = email[:at]
host = email[at + 1:]
# initialize entry
if host not in hosts:
hosts[host] = []
# increment/append
users = hosts[host]
users.append(username)
return hosts
email_hosts(['[email protected]', '[email protected]', '[email protected]', '[email protected]'])
{'gmail.com': ['abby', 'rachel'],
'yahoo.com': ['kumar'],
'byu.edu': ['zappala']}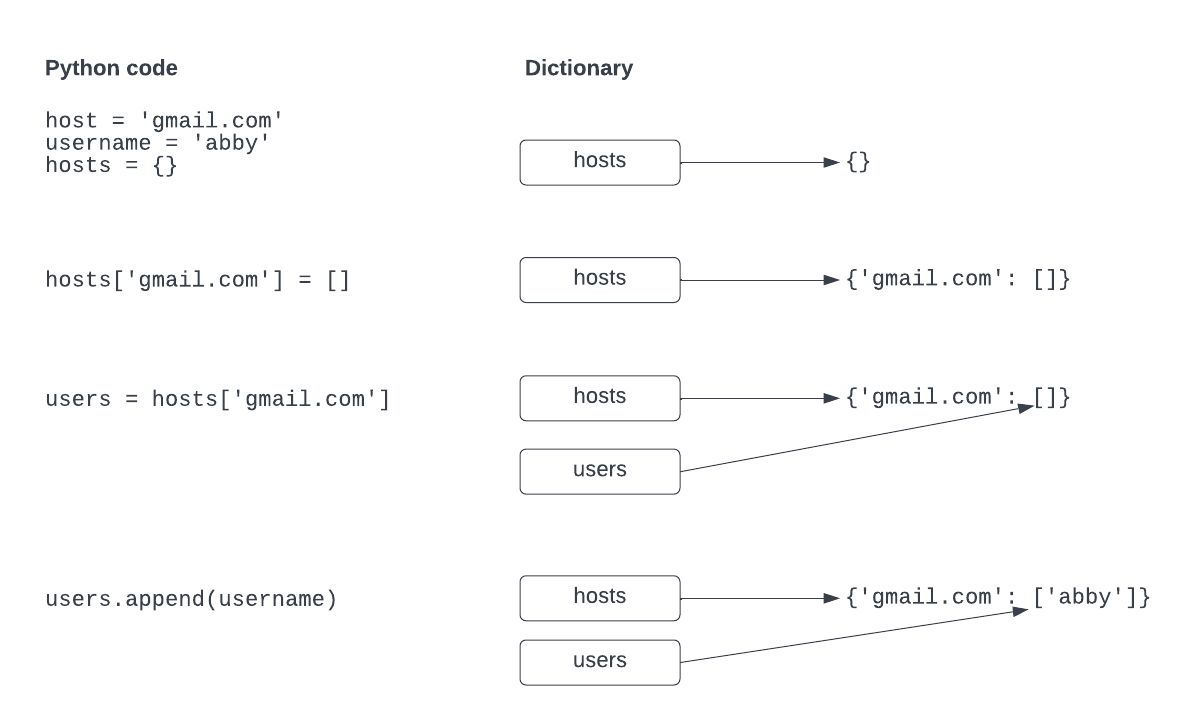
Example — food ratings
- we have a list of anonymous food ratings:
['donut:10', 'apple:8', 'donut:9', 'apple:6', 'donut:7']- build a dictionary that lists all the ratings for the same food
{
'donut': [10, 9, 7],
'apple': [8, 6]
}def food_ratings(ratings):
foods = {}
for food_rating in ratings:
at = food_rating.find(':')
food = food_rating[:at]
rating = food_rating[at + 1:]
# convert to integer
rating = int(rating)
# initialize entry
if food not in foods:
foods[food] = []
# increment/append
foods[food].append(rating)
return foods
food_ratings(['donut:10', 'apple:8', 'donut:9', 'apple:6', 'donut:7', 'dr. zappalas lasagna:100']) {'donut': [10, 9, 7], 'apple': [8, 6], 'dr. zappalas lasagna': [100]}Example — census names
-
we want to store both the last name and first name in the dictionary
-
a single person:
['Zappala', 'Anna']- a list of people:
[['Zappala', 'Mariano'], ['Zappala', 'Anna']]- a list of lists!
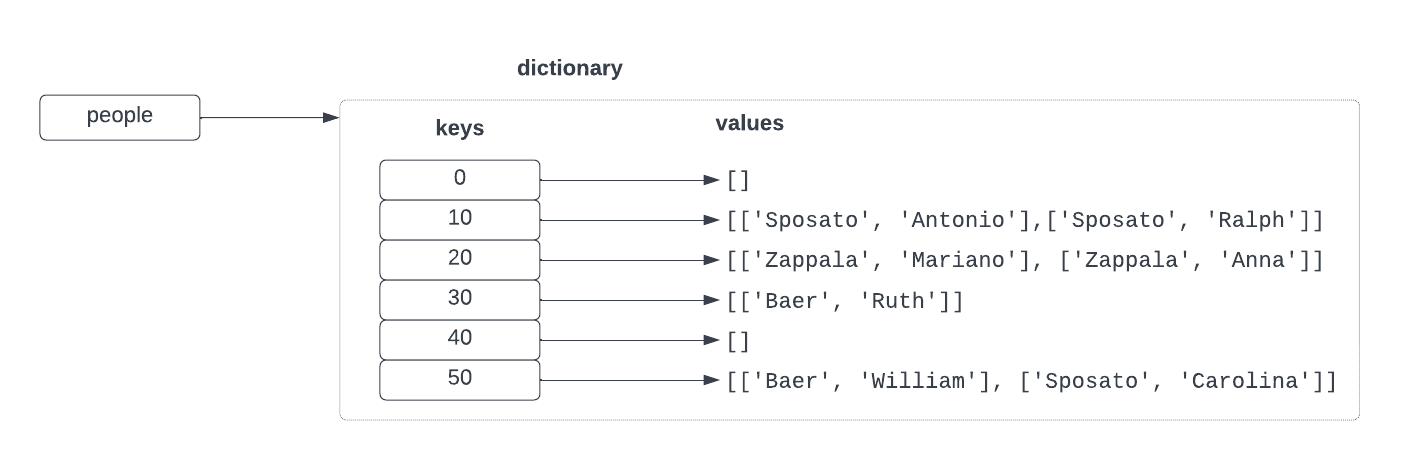
def people_by_age(filename):
people = {}
with open(filename) as file:
for line in file:
last, first, relationship, gender, race, age, marital_status = line.strip().split(',')
age = int(age)
# rounds to nearest 10s
age_group = round_to_nearest_10(age)
# initialize a new entry
if age_group not in people:
people[age_group] = []
# append a new person
people[age_group].append([last, first])
return people
people_by_age('census.txt') {50: [['Baer', 'William'], ['Sposato', 'Carolina']],
30: [['Baer', 'Ruth']],
10: [['Baer', 'Robert'],
['Baer', 'William'],
['Sposato', 'Antonio'],
['Sposato', 'Ralph']],
20: [['Sposato', 'Albert'],
['Sposato', 'Carlo'],
['Sposato', 'Frances'],
['Zappala', 'Mariano'],
['Zappala', 'Anna']]}Dictionaries vs lists
- lists are for when you want to store a set of things
- you can directly access each item with an index, which is always an integer starting at 0
- often want to access all of them (e.g. with a for loop)

- dictionaries are for when you want to map a key to a value
- you can directly access each item with a key, which an be any integer or string you choose
- often want to access one at a time (e.g. look up the total number of 20-year-olds in the census)
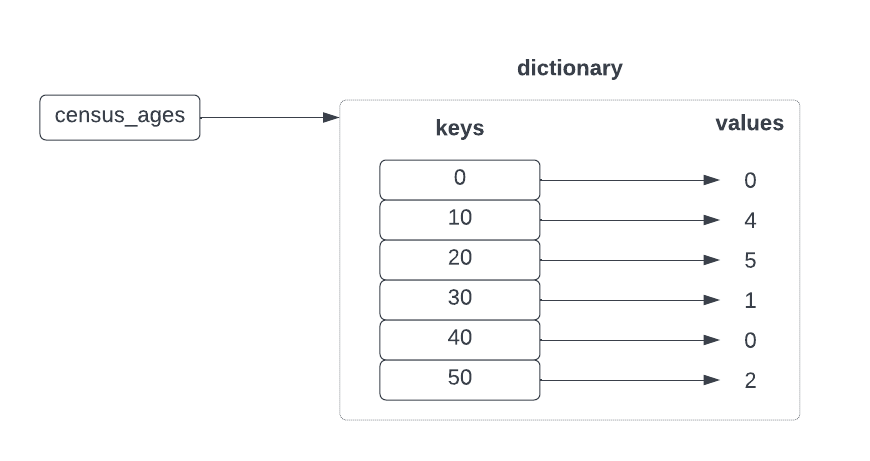
- can combine these!
- a dictionary that holds a list of lists

A dictionary of dictionaries
We spent some time in class talking about how the entries in a dictionary can be … a dictionary. See the below code, which creates a dictionary of people in the census.
def dictionary_of_people_by_age(filename):
"""
Create a dictionary of people by age. The keys are age group, and the values
are a dictionary that contains last name, first name, gender, and age.
:param filename: a file that contains census data
:return: a dictionary as described above
>>> dictionary_of_people_by_age('census.txt')
{50: [{'last': 'Baer', 'first': 'William', 'gender': 'M', 'age': 51}, {'last': 'Sposato', 'first': 'Carolina', 'gender': 'F', 'age': 53}], 30: [{'last': 'Baer', 'first': 'Ruth', 'gender': 'F', 'age': 38}], 10: [{'last': 'Baer', 'first': 'Robert', 'gender': 'M', 'age': 12}, {'last': 'Baer', 'first': 'William', 'gender': 'M', 'age': 10}, {'last': 'Sposato', 'first': 'Antonio', 'gender': 'M', 'age': 18}, {'last': 'Sposato', 'first': 'Ralph', 'gender': 'M', 'age': 10}], 20: [{'last': 'Sposato', 'first': 'Albert', 'gender': 'M', 'age': 23}, {'last': 'Sposato', 'first': 'Carlo', 'gender': 'M', 'age': 21}, {'last': 'Sposato', 'first': 'Frances', 'gender': 'F', 'age': 28}, {'last': 'Zappala', 'first': 'Mariano', 'gender': 'M', 'age': 27}, {'last': 'Zappala', 'first': 'Anna', 'gender': 'F', 'age': 25}]}
"""
people = {}
with open(filename) as file:
for line in file:
last, first, relationship, gender, race, age, marital_status = line.strip().split(',')
age = int(age)
age_group = round_to_nearest_10(age)
# initialize a new entry
if age_group not in people:
people[age_group] = []
# append a new person
people[age_group].append({'last': last, 'first': first, 'gender': gender, 'age': age})
return people