
Using the Internet
This is what the Arpanet (the precurser to the Internet) looked like in December 1969. You can think of it like a graph — nodes and edges, communicating with each other.
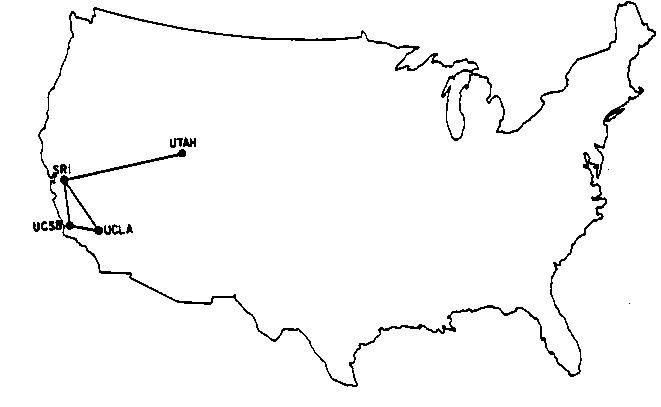
Here is what the network of a worldwide Internet Service provider looks like. This is what just what one company operates. The Internet is a bunch of these connected in many places.
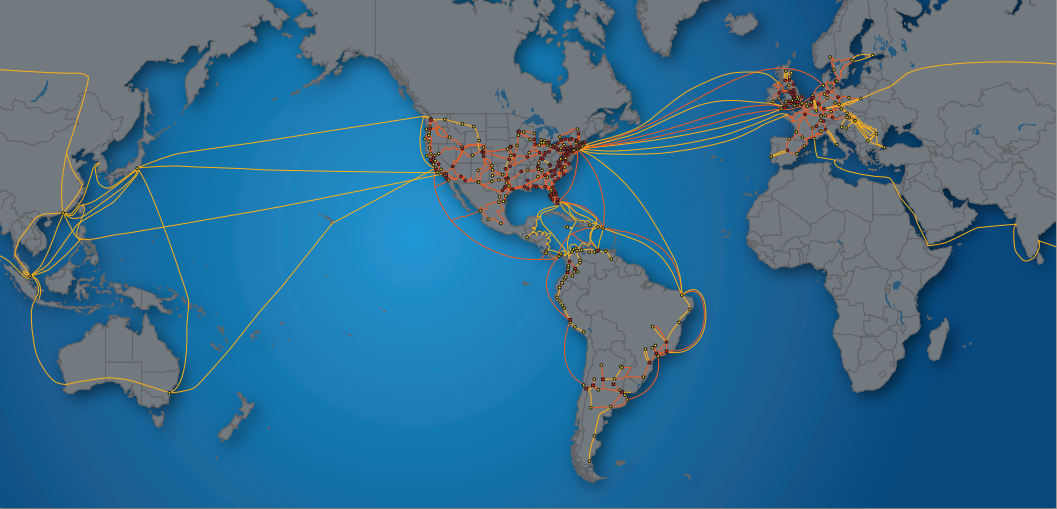
When you zoom out, this is kind of what the Internet looks like. This is really only part of it, and the image pre-dates our world of smart toasters and smart doorbells and smart speakers.

From your perspective, the Internet is a system that lets your devices connect to various sites on the Internet:
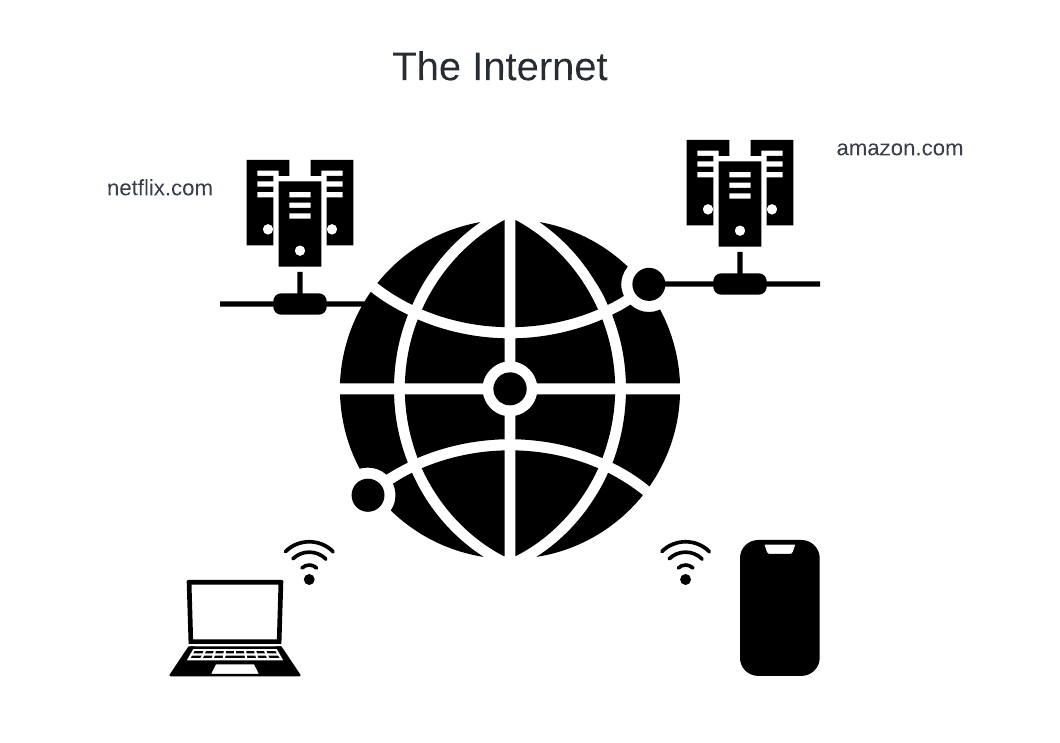
When you use a web browser, you’re connecting from your machine to some other machine on the Internet.
An important part of this is the URL shown in the URL bar:

scheme: https (secure HTTP)hostname: www.neflix.compath: /browse
What if I told you that you could write a one-line Python program to download anything you want from the Internet?

You will need to install the requests library:
pip install requestsNow you can download anything:
import requests
response = requests.get('https://www.google.com/')OK, but what’s in the response?
One important thing is the status code:
response.status_code- 200: OK - Successfully downloaded the item
- 301: Moved - That item is at a different URL now
- 403: Forbidden - You are not authorized to access that item
- 404: Not Found - Couldn’t find anything at that URL
- 500: Server Error - The server hosting that item has crashed
response = requests.get('https://amazon.com/something/that/probably/doesnt/exist.html')
response.status_codeAnother important thing is the item itself. This is Google’s home page:
response = requests.get('https://www.google.com/')
response.textLet’s do something more useful:
import requests
from byuimage import Image
# download the comic
response = requests.get('https://imgs.xkcd.com/comics/galaxies_2x.png')
# write the comic to a file -- use 'wb' because we are 'writing binary'
# note that we want to use response.content instead of response.text because this is not a text file
with open('galaxies_2x.png', 'wb') as file:
file.write(response.content)
# load the image with the image library and show it
image = Image('galaxies_2x.png')
image.show()APIs
(Not important) API stands for Application Programming Interface
(Important) If a web site supports an open API, it is providing a way for you to access its resources
Let’s look at an example: cat facts
-
hostname: https://cat-fact.herokuapp.com
-
path: /facts/random — get a random fact
/facts/random is also called an “endpoint”
hostname = 'https://cat-fact.herokuapp.com'
response = requests.get(hostname + '/facts/random')
if response.status_code == 200:
print(response.text)
else:
print(f"error: {response.status_code}")We got back a dictionary! In string form!
This is JSON. It is one of a handful of common formats used to exchange structured information on the web. We can convert it into a Python dictionary using:
cat_fact = response.json()
print(cat_fact)Let’s print it in a more nicely formatted way:
import json
formatted = json.dumps(response.json(), indent=4)
print(formatted)We can get the fact with:
cat_fact['text']So now we can do this:
def get_random_fact():
hostname = 'https://cat-fact.herokuapp.com'
response = requests.get(hostname + '/facts/random')
if response.status_code == 200:
cat_fact = response.json()
return cat_fact['text']
else:
return f"error: {response.status_code}"
print(get_random_fact())
print(get_random_fact())
print(get_random_fact())There is lots more we can do with this API
- /facts/random/?animal_type=horse — get a random fact about a horse (or substitute some other animal type)
- /facts/random/?amount=2 — get two random facts (or substitute some other number)
- /facts/random/?animal_type=cat&amount=3 — get three random facts about a cat
Everything after a ? is called a parameter. They have the format
keyword=value. You combine them with &.
hostname = 'https://cat-fact.herokuapp.com'
url = f"{hostname}/facts/random/?animal_type=cat&amount=3"
response = requests.get(url)
print(response.json())
Notice that we get back a list of cat facts!
def get_random_cat_facts(number):
# initialize a result list
results = []
# setup the url
hostname = 'https://cat-fact.herokuapp.com'
url = f"{hostname}/facts/random/?animal_type=cat&amount={number}"
# make the request
response = requests.get(url)
if response.status_code == 200:
cat_facts = response.json()
for fact in cat_facts:
results.append(fact['text'])
return results
else:
return f"error: {response.status_code}"
print(get_random_cat_facts(5))If you know the ID of a fact you can get it directly:
- /facts/:factID
def get_fact(fact_id):
hostname = 'https://cat-fact.herokuapp.com'
url = f"{hostname}/facts/{fact_id}"
response = requests.get(url)
if response.status_code == 200:
cat_fact = response.json()
return cat_fact['text']
else:
print(f"error: {response.status_code}")
fact_id = '621563361cf2c5b445eb4a6c'
print(get_fact(fact_id))The Star Wars API
- base URL: https://www.swapi.tech/api
- /films
- /people
- /planets
- /species
- /starships
- /vehicles
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/films')
print(response.json())Let’s make this look prettier:
import json
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/films/1')
formatted = json.dumps(response.json(), indent=4)
print(formatted)What is the path to get the characters in the film?
What is the path to get the planets in the film?
What is the path to get the opening crawl of the film?
So now we can print out some of the information about a Star Wars film
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/films/1')
film = response.json()
print(film['result']['properties']['title'])
print('\n')
print(film['result']['properties']['opening_crawl'])Notice that the film has a list of URLs for characters, planets, spaceships, etc. Let’s look at the characters.
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/films/1')
film = response.json()
characters = film['result']['properties']['characters']
print(characters)We can use these URLs to find out information about each of the people in the film.
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/people/1')
print(response.json())And likewise we can find out about the planets:
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/planets/1')
print(response.json())Let’s put it all together!
def get_character_and_home_world(url):
character = requests.get(url).json()
name = character['result']['properties']['name']
homeworld_url = character['result']['properties']['homeworld']
homeworld = requests.get(homeworld_url).json()
world = homeworld['result']['properties']['name']
return (name, world)
def print_film_and_characters(film_id):
base = 'https://www.swapi.tech/api'
response = requests.get(base + '/films/1')
film = response.json()
print(film['result']['properties']['title'])
print('\n')
character_urls = film['result']['properties']['characters']
for url in character_urls:
(name, world) = get_character_and_home_world(url)
print(f"{name}: {world}")
print_film_and_characters(1)If you want to check out other APIs, see Public APIs.
You are ready to use any API that lists “No” for “Auth”, meaning they don’t require authentication (an account). If you want to do a little more learning, you could try one that requires an API Key for authentication. You will need to learn how to get a key and how to send it in your requests. Those requiring OAuth will require significantly more work to understand (not recommended at this point).